Als Beispiel für supervised learning schauen wir uns den ML-Algorithmus k-nearest-neighbors an.
Problem
Pilzsammler Heinz-Wilhelm kommt vom Pilzsammeln aus dem Böhmerwald nach Hause. Er hat 14 Stück gefunden und möchte diese überprüfen lassen. Also bringt er sie zum Pilzkontrolleur nach Bad Leonfelden. Dieser schaut sich die Pilze an und findet unter den 14 Exemplaren 7 essbare Wiesenchampignons, 6 giftige Karbolchampignons und sogar einen tödlichen Grünen Knollenblätterpilz!



Heinz-Wilhem möchte nicht immer zum Kontrolleur und informiert sich, wie man die Pilze voneinander unterscheiden kann: Sie unterscheiden sich primär in der Farbe der Lamellen. Weitere Merkmale sind Fleischverfärbungen und Geruchsunterschiede.
Heinz-Wilhelm macht sich an die Arbeit und baut eine Maschine…
Merkmale
Die Maschine, die Heinz-Wilhelm gebaut hat, untersucht die Farbe der Lamelle und die Fleischverfärbung und liefert zwei Zahlenwerte zurück. Heinz-Wilhelm erhält für die 14 kontrollierten Pilze die folgenden Werte:
| Pilz | Messwerte | |
|---|---|---|
| Lamellen | Fleisch | |
| Karbolchampignon | 1 | 2 |
| Karbolchampignon | 0.5 | 3 |
| Karbolchampignon | 1.25 | 4 |
| Karbolchampignon | 2.3 | 1.75 |
| Karbolchampignon | 1 | 2.3 |
| Karbolchampignon | 2.5 | 3.1 |
| Knollenblätter | 1.5 | 6 |
| Wiesenchampignons | 5.5 | 7 |
| Wiesenchampignons | 6 | 5.5 |
| Wiesenchampignons | 5.5 | 7.25 |
| Wiesenchampignons | 4.5 | 6.75 |
| Wiesenchampignons | 4.5 | 6.25 |
| Wiesenchampignons | 4.75 | 6.5 |
| Wiesenchampignons | 5.1 | 7.5 |
Heinz-Wilhelm zeichnet die gemessenen Werte in einem Koordinatensystem auf. Er markiert die essbaren Champignons mit grüner Farbe und die ungeniessbaren und giftigen Pilze mit rot.
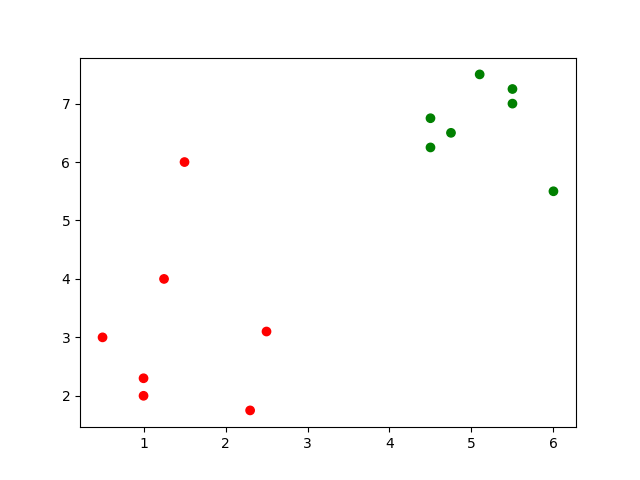
Aufgabe
Was kann er damit aussagen? Ist diese Maschine gut? Sind die Merkmale gut?
Werte grafisch darstellen
Die matplotlib von Python ermöglicht es, diese Punkte im Koordinatensystem darzustellen:
Aufgabe: pyplot
Übernimm das untenstehende Skript und analysiere es. Starte es in Thonny. Verstehst du die unterhalb notierten Anmerkungen?
import matplotlib.pyplot as plt
data = [
(1, 2 ,"red"),
(0.5, 3 ,"red"),
(1.25, 4 ,"red"),
(2.3, 1.75 ,"red"),
(1, 2.3 ,"red"),
(2.5, 3.1 ,"red"),
(1.5, 6 ,"red"),
(5.5, 7 ,"green"),
(6, 5.5 ,"green"),
(5.5, 7.25 ,"green"),
(4.5, 6.75 ,"green"),
(4.5, 6.25 ,"green"),
(4.75, 6.5, "green"),
(5.1, 7.5, "green")
]
x_points = [x[0] for x in data]
y_points = [x[1] for x in data]
colors = [x[2] for x in data]
plt.scatter(x_points, y_points, color=colors)
plt.show()
plt.close()- Zeile 1
pyplotwird abgekürzt alspltimportiert- ab Zeile 3
- eine Liste von Punkten wird definiert
- die Punkte sind Tupel (runde Klammern von zwei Werten, x- und y-Koordinate des Punktes)
- Zeile 20+21
- die Liste der Punkte wird in zwei Listen geteilt: eine Liste aller x-Koordinaten und eine Liste aller y-Koordinaten
- dieser Schritt ist wegen dem Zeichenbefehl von
pyplotnötig - Zeile 23
- die Punkte werden als Punktwolke (scatter-Plot) gezeichnet
- Zeile 25
- das Plot-Fenster wird angezeigt
- Zeile 26
- es wird signalisiert, dass der Zeichenvorgang beendet ist
Anwendung
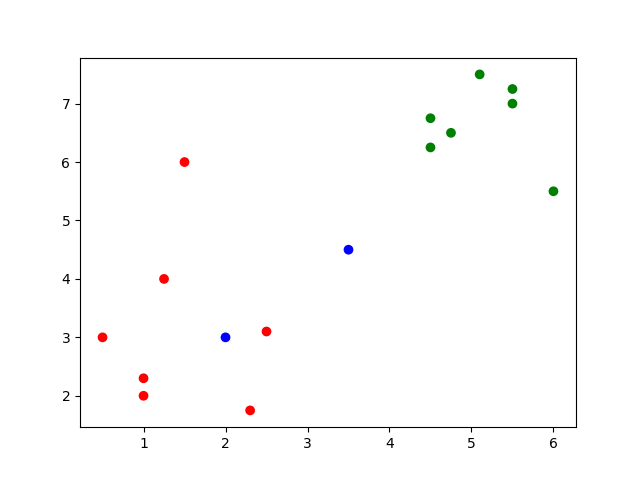
Die oben genannten Punkte stellen unsere Trainingsdaten dar. Was geschieht jetzt, wenn wir einen neuen Punkt erhalten? Können wir diesen eindeutig einer der beiden Kategorien zuordnen?
Aufgabe: neue Pilze
Er findet zwei weitere Pilze und misst diese: Kannst du die Werte für Heinz-Wilhelm hinzufügen und blau darstellen?
(2, 3), (3.5, 4.5)
Zu welcher Kategorie würdest du die neuen Pilze zählen? geniessbar oder giftig?
Lösung: neue Pilze
import matplotlib.pyplot as plt
data = [
(1, 2 ,"red"),
(0.5, 3 ,"red"),
(1.25, 4 ,"red"),
(2.3, 1.75 ,"red"),
(1, 2.3 ,"red"),
(2.5, 3.1 ,"red"),
(1.5, 6 ,"red"),
(5.5, 7 ,"green"),
(6, 5.5 ,"green"),
(5.5, 7.25 ,"green"),
(4.5, 6.75 ,"green"),
(4.5, 6.25 ,"green"),
(4.75, 6.5, "green"),
(5.1, 7.5, "green")
]
test = [
(2, 3, "blue"),
(3.5, 4.5, "blue")
]
x_points = [x[0] for x in data+test]
y_points = [x[1] for x in data+test]
colors = [x[2] for x in data+test]
plt.scatter(x_points, y_points, color=colors)
plt.show()
plt.close()k-nearest-neighbors
Der k-nearest-neighbors-Algorithmus ist ein Klassifikationsalgorithmus. Er kann für Probleme wie z.B. die Klassifikation der beiden neuen Pilze bei Heinz-Willhelm eingesetzt werden.
Definition: k-nearest-neighbors
Die Klassifikation eines Objekts
Aufgabe: «Tabelle»
Wende den Algorithmus auf die Pilz-Daten an. Du kannst das folgende Bild verwenden und dieses mit Zirkel (oder Kreisen in Word oder so) vermessen.
Trage in der untenstehenden Tabelle für jedes notierte k pro Punkt die Anzahl roter nearest neighbors und die Anzahl grüner nearest neighbors sowie die daraus resultierende Klassifikation giftig/geniessbar ein.
| Punkt (2, 3) | Punkt (3.5, 4.5) | ||||||
|---|---|---|---|---|---|---|---|
| #rot | #grün | Klass. | #rot | #grün | Klass. | ||
| k=1 | |||||||
| k=2 | |||||||
| k=3 | |||||||
| k=4 | |||||||
Diskutiere die Klassifikation der Punkte in Abhängigkeit von k. Gibt es besser- oder weniger gut-gewählte Werte für k? Wovon hängt dies ab?
Python
Das Paket scikit-learn beinhaltet eine Implementation des K-Nearest-Neighbor-Algorithmus. Wir können dieses relativ einfach auf unserer bereits vorhandenen Daten anwenden: Dabei trainieren wir mit den «grünen» und «roten» Punkten und versuchen dann die beiden «blauen» Punkte (also die neuen Pilze), der roten oder grünen Kategorie zuzuweisen:
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
data = [
(1, 2 ,"red"),
(0.5, 3 ,"red"),
(1.25, 4 ,"red"),
(2.3, 1.75 ,"red"),
(1, 2.3 ,"red"),
(2.5, 3.1 ,"red"),
(1.5, 6 ,"red"),
(5.5, 7 ,"green"),
(6, 5.5 ,"green"),
(5.5, 7.25 ,"green"),
(4.5, 6.75 ,"green"),
(4.5, 6.25 ,"green"),
(4.75, 6.5, "green"),
(5.1, 7.5, "green")
]
test = [
(2, 3, "blue"),
(3.5, 4.5, "blue")
]
x_points = [x[0] for x in data+test]
y_points = [x[1] for x in data+test]
colors = [x[2] for x in data+test]
X_train = [x[0:2] for x in data]
y_train = [x[2] for x in data]
print(y_train)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
X_test = [x[0:2] for x in test]
predict = knn.predict(X_test)
print(predict)
plt.scatter(x_points, y_points, color=colors)
plt.show()
plt.close()- Zeilen 30 & 31
- Wir bereiten die Trainingdaten vor
X_trainbeinhaltet alle Merkmalsverktoren (also eigentlich die Koordinaten der Punkte)Y_trainist das Label, also zu welcher Kategorie der Punkt gehört- Zeile 34
- Der sogenannte Classifier wird vorbereitet und der Wert für
kwird über das keyword-Argumentn_neighborsauf3gesetzt - Zeile 35
- Der Classifier wird trainiert
- Zeilen 37
- Die Testdaten werden für den Einsatz vorbereitet. Dabei wird das Label entfernt
- Zeile 39 & 40
- Der Classifier soll eine Vorhersage für die beiden neuen Punkte liefern und ausgeben
Aufgabe
Teste das obenstehenden Programm in Thonny – ev. musst du das Package sklearn installieren.
Variiere wiederum den Wert für k und überprüfe damit deine von Hand erstellte Tabelle aus der letzten Aufgabe.
Andreas Kunze via Wikimedia Commons (CC BY-SA 3.0) ↩︎
James Lindsey at Ecology of Commanster via Wikimedia Commons (CC BY-SA 2.5) ↩︎
Ak ccm via Wikimedia Commons (CC BY-SA 3.0) ↩︎